A Proof of Ostrowski’s Theorem
So this coming Friday I’ve been asked to be a backup speaker for the local maths club, in case our current speaker cancels (again). Since I like cake, and I like to be given a fairly sliced piece of cake, I decided to talk about Sperner’s lemma and it’s applications to fair division problems.
This stuff is very well known, and there’s a popular expository article about it here. So I won’t talk too much about that.
On the other hand, something I will talk about is a fantastic related problem with an equally fantastic solution. It goes something like this. Suppose you have a square cake; for which integers 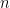
This was first posed in the American Mathematical Monthly after (I assume) a heated debate during somebody’s birthday celebrations. It was eventually solved by a mathematician named Paul Monsky in 1970, with an astonishingly clever mix of combinatorics and valuation theory.
It’s quite easy to show that you can perform such a division for even 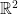
None of this is too astonishing. What really surprised me, however, is that to construct such a colouring he uses (of all things!) 
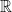
Another paper on similar colourings of projective planes also finds strong links to non-archimedian valuations, which leads me to believe that there is something very strange going on here! I haven’t read this later paper very closely, but I really should.
In any case, these things have gotten me thinking a lot about different kinds of norms on 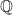
Theorem 1 Every non-trivial valuation on
or one of the
.
This is pretty cool, and I think it provides some motivation as to why we should care about
Definition 2 A valuation on a field
is a map
satisfying:
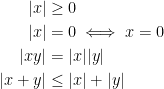
A valuation is non-archimedian if it satisfies the ultrametric inequality:

We also say that two valuations 



The standard valuation
Any rational can be written in the form 



Ostrowski’s theorem asserts that these are essentially the only valuations we can find on
Lemma 3 Suppose
is a non-trivial valuation on
, we have:

Proof: Note that 





We can now apply the tensor power trick. Replace 

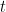
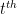
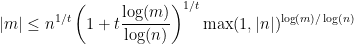
Taking the limit as 

Another useful lemma we will need is the following characterisation of non-archimedian valuations over
Lemma 4
for all
.
Proof: The forwards direction is trivial, so suppose 

Taking 
We are now in a position to prove the archimedian side of the proof directly:
Theorem 5 If
Proof: First of all, we note that 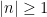
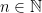


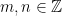
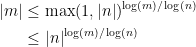
Hence 


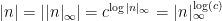
Finally, a cute algebraic proof wraps up the non-archimedian part of Ostrowski’s theorem.
Theorem 6 If
Proof: Consider the set 




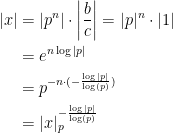
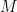 is an
is an 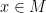 , there exists a neighbourhood
, there exists a neighbourhood  of
of  .
.
 with
with  . We can consider
. We can consider 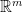 for some
for some  in the usual way:
in the usual way:
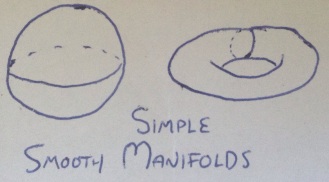
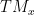 , the tangent space of
, the tangent space of 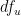 .
.
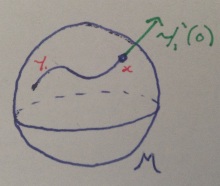
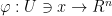 . Let
. Let 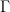 be the set of curves
be the set of curves 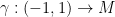 such that
such that 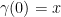 and
and 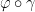 is differentiable at
is differentiable at  in the usual sense. We can form an equivalence relation
in the usual sense. We can form an equivalence relation  on
on 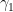 and
and  to be equivalent if
to be equivalent if 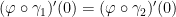 . Then
. Then 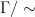 .
.
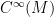 be the set of functions
be the set of functions 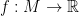 such that, for any smooth coordinate chart
such that, for any smooth coordinate chart 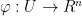 , the composition
, the composition 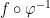 is smooth.
is smooth.  in the obvious way.
in the obvious way.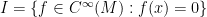 . This set is the kernel of the evaluation homomorphism
. This set is the kernel of the evaluation homomorphism 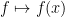 , and so is in fact an ideal of
, and so is in fact an ideal of 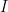 is a maximal ideal.
is a maximal ideal. -dimensional case. As the functions in
-dimensional case. As the functions in 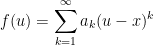
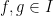 have the same first order behaviour, or derivative, at
have the same first order behaviour, or derivative, at 
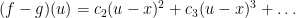
 . To identify them, we need merely quotient!
. To identify them, we need merely quotient! of
of 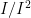 .
.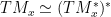
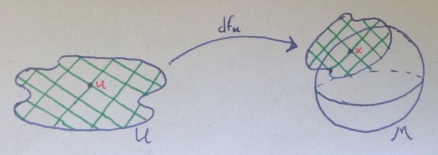
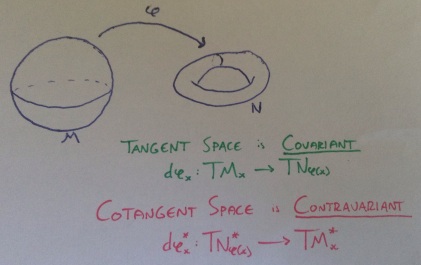
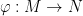 between two smooth manifolds. The derivative of this function gives rise to a map
between two smooth manifolds. The derivative of this function gives rise to a map 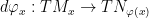 – for a nice exercise, try to define this!
– for a nice exercise, try to define this!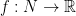 in
in  . Pulling back along
. Pulling back along 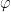 , we get a map
, we get a map 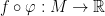 which vanishes at
which vanishes at 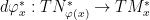 .
.
 be a collection of subsets of a space
be a collection of subsets of a space  such that the interiors cover
such that the interiors cover 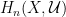 generated by all singular cubes contained within some
generated by all singular cubes contained within some 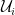 . Then the inclusion
. Then the inclusion 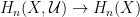 is an isomorphism.
is an isomorphism. such that every ball of radius
such that every ball of radius  is covered by some set in the cover. Of course, this relies on the fact that a cube is a metric space.
is covered by some set in the cover. Of course, this relies on the fact that a cube is a metric space.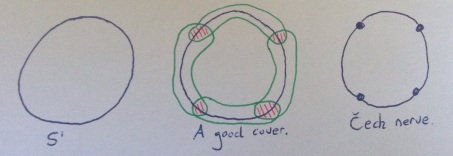
 -cobordism and where we stand with the classification of
-cobordism and where we stand with the classification of